主页(http://www.kuwanit.com):机器学习硬件展望:专用化是大势所趋
已被英特尔收购的公司 Nervana Systems 在这种任务的硬件开发上取得了领先。Nervana 计算机科学家 Scott Leishman 表示 Nervana Engine 是一款 ASIC 的深度学习加速器,其将在 2017 年初期到中期的时候投入生产。Leishman 指出另一个计算密集型任务——比特币挖矿(bitcoin mining),就曾经从 CPU 实现转向 GPU,然后转向 FPGA 并最终转向了 ASIC,因为定制的硬件能够实现更优的能量效率。他说:「我认为同样的情况正在深度学习领域发生。」
「今天所有人都在做深度学习,」斯坦福大学 Concurrent VLSI Architecture 研究组的领导者兼英伟达首席科学家 William Dally 说。他说这从他的角度来看是不足为奇的。「GPU 几乎和你想象的一样美好。」
事实上,GPU 在 2009 年的时候就已经在驱动人工神经网络了,那时候斯坦大学的一些研究者证明这种硬件使得深度神经网络的训练时间很适宜。(参阅论文《Large-scale Deep Unsupervised Learning using Graphics Processors》)
谷歌的一位硬件工程师 Norm Jouppi 在这场围棋大战的两个月后宣布了张量处理单元的存在,并解释说谷歌的数据中心已经使用这些新型加速器一年多了。谷歌还没有公布这些集成板上到底有什么奥妙,但毫无疑问的是,这代表着加速深度学习计算上的一个日益流行的策略:使用专用集成电路(ASIC)。
Dally 说,深度学习硬件的第二个任务(大为异于第一个任务)是「数据中心中的推理」。「推理(inference)」这个词在这里的意思是:用于之前任务的已训练的基于云的人工神经网络在同样的任务上能进行持续运算。谷歌的神经网络每天都要执行天文数字级别的推理计算,以帮助用户分类图片、翻译语言和识别口语等等。尽管外界还不能百分之百确定,但可以推理谷歌的张量处理单元应该在为这些计算提供助力。
加满油门:谷歌的 TPU 正在该公司的服务器里加速深度学习计算
2016 年 3 月份,谷歌 DeepMind 的计算机在多轮围棋比赛中击败了世界围棋冠军李世乭。这一事件标志着人工智能领域内的一个新里程碑。获胜的 AlphaGo 借力于现在为大家所熟知的深度学习——一种人工神经网络;在这种神经网络里有很多计算处理层,可以用来自动寻找问题的解决方案。
Dally 补充说:「三个支撑深度学习关键任务的最后一个任务就是在嵌入式设备里进行推理,」比如智能手机、相机和平板电脑。对于这些应用,关键是实现低能耗的专用集成电路(ASIC)。在即将来到的一年,深度学习软件将会越来越多的实现手机端应用,比如目前已有的手机端应用——恶意软件检测以及图片中的文字翻译。
训练和推理常常需要运用不同的技能设置。通常对训练的设置上,机器必须能够实施精确度相对较高的计算,常使用 32 位的浮点计算。对于推理,则可以牺牲精确度以获取更快的速度和更低的功耗。「这是研究领域里一个很活跃的区域,」Leishman 说道。「你能达到的最低限度是多少?」
虽然目前有很多因素促使硬件设计来加速深度神经网络的计算,但巨大的风险依然并存:如果神经网络的进步太快,所设计来运行过往的神经网络的芯片在出厂时就会过时。「算法正以非常快的速度改变,」Dally 说。「所有从事构建这些硬件的人都在试图赢得这场赌注。」
Dally 解释说有三个独立的领域需要考虑。第一是他所说的「数据中心中的训练」。他认为任何深度学习系统的第一步都是:调节神经元之间大约数百万个连接以使网络能够完成分配给它的任务。
那时候人们还不知道谷歌正在悄然开发为这一胜利提供助力的秘密武器——一种专用硬件,在谷歌用于击败世界冠军李世乭的计算机里已有这种特殊硬件。这种硬件被谷歌称为张量处理单元(TPU/Tensor Processing Unit)。
企业(主要是微软)追求的另一个战术是使用现场可编程门阵列(FPGA),其有可重配置的优势,可以根据计算需求进行修改。而更常见的方法则是使用图形处理单元(GPU),这种计算设备可以并行地同时执行大量数学运算。最知名的 GPU 提供商英伟达(NVIDIA)近段时间以来的股价飞涨也正是得益于此。
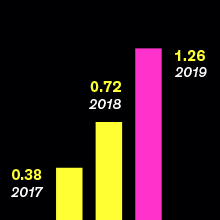
来自深度学习软件的收入很快就将超过十亿美元(单位:十亿美元;来源: Tractica)
来自:机器之心

虽然 Dally 谢绝泄露英伟达的特别计划,但他指出英伟达的 GPU 正在完成升级。英伟达的早期版本——Maxwell 的架构能够进行双精度(64 位)和单精度(32 位)的计算,而目前的 Pascal 架构则增加了处理 16 位运算的能力,支持双倍输入且效率也是之前单精度计算的两倍。所以不难想象英伟达最终将会推出能进行 8 位运算的 GPU,这样的 GPU 将是在云端进行推理运算的理想硬件,因为对云端推理来说能源效率是控制成本的关键因素。
除此之外,无人机生产商大疆(DJI)已经开始在其幽灵 4(Phantom 4)无人机中使用与专用集成电路的深度学习相类似的器件,大疆所使用的器件是一个由加州厂商 Movidius 制造的特殊视觉处理芯片,这个芯片用来识别障碍物。(Movidius 同时也是英特尔最近收购的另一家神经网络相关的公司)。与此同时高通(Qualcomm)在其 Snapdragon 820 处理器里放置了一个特殊的电路系统来更好地执行深度学习运算。


发表评论愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。