主页(http://www.kuwanit.com):时不我待,NVIDIA推出GPU加速平台RAPIDS提升机器学习效率
赵立威介绍RAPIDS 构建于 Apache Arrow、pandas 和 scikit-learn 等流行的开源项目之上,为最流行的Python 数据科学工具链带来了 GPU 提速。为了将更多的机器学习库和功能引入 RAPIDS,NVIDIA 广泛地与开源生态系统贡献者展开合作 ,其中包括 Anaconda、BlazingDB、Databricks、Quansight、scikit-learn、Ursa Labs 负责人兼 Apache Arrow 缔造者 WesMcKinney 以及迅速增长的 Python 数据科学库 pandas 等等。
图 NVIDIA亚太区解决方案架构高级总监赵立威
“数据分析和机器学习是高性能计算市场中最大的细分市场,不过目前尚未实现加速。”NVIDIA 创始人兼首席执行官黄仁勋在 GPU 技术大会主旨演讲中表示,“全球最大的行业均在海量服务器上运行机器学习算法,目的在于了解所在市场和环境中的复杂模式,同时迅速、精准地做出将直接影响其基础的预测。”
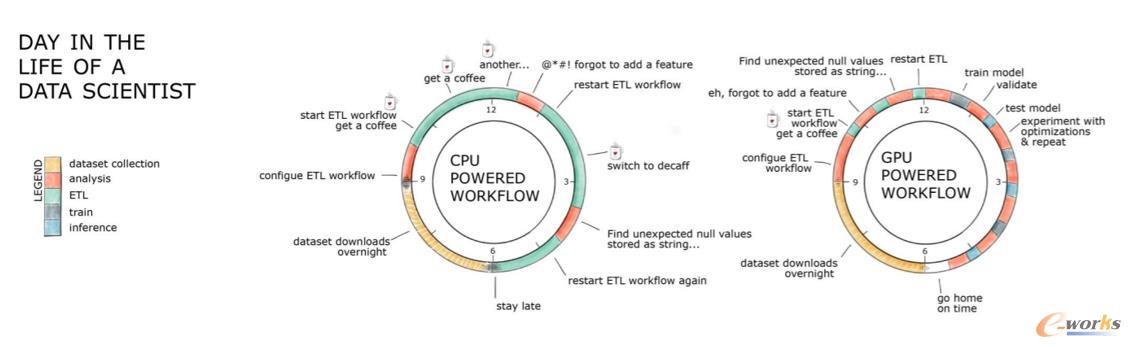
图 数据科学家应用RAPIDS的日常对比
无忧一体化:只需要使用最少的代码加速Python数据科学工具链,不需要重新编码或者使用新工具;

从硬件的角度,除了NVIDIA的DGX-2、DGX-1、DGX station外,RAPIDS还包括一系列合作伙伴基于HGX-1、HGX-2两种架构提供的硬件产品。此外,NVIDIA也在跟下游的ODM、OEM厂商合作,进一步拓展RAPIDS的运行和使用。
在任何GPU上扩展:从GPU工作站到多GPU服务器的无缝扩展多节点集群;
在这种趋势下,NVIDIA于今年10月10日的GPU 技术大会上发布了一款针对数据科学和机器学习的 GPU 加速平台--- RAPIDS。日前,NVIDIA在京召开了媒体沟通会,系统讲解了RAPIDS的应用场景、平台性能和生态策略。在NVIDIA亚太区解决方案架构高级总监赵立威看来,RAPIDS能够帮助超大规模公司以前所未有的速度分析海量数据并进行精准的业务预测,显著提升端到端预测数据分析能力。
随着大数据技术的快速发展,不管是在数据处理还是训练的过程,都需要大量的计算力,而在后摩尔时代,数据的增长量远远超过了计算力,基于Hadoop、SPARK的分布式节点加速会越来越困难。赵立威表示虽然市场出现了GPU Data base技术,但并没有把数据的准备、操作、ETL过程和机器学习训练整合成一个pipeline。对于GPU加速深度学习而言,它本质是加速了计算的应用,而数据分析和机器学习目前是最大的HPC应用分支,伴随着未来高速增长,它对计算力有着巨大的需求。对此,NVIDIA推出GPU 加速平台RAPIDS,该平台已与全球最流行的数据科学库及工作流无缝整合,可加速机器学习,如包括Anaconda、BlazingDB、Graphistry、NERSC、PyData、INRIA和Ursa Labs在内的主要开源贡献者,都在RAPIDS推出后立即给予了其广泛的生态系统支持。
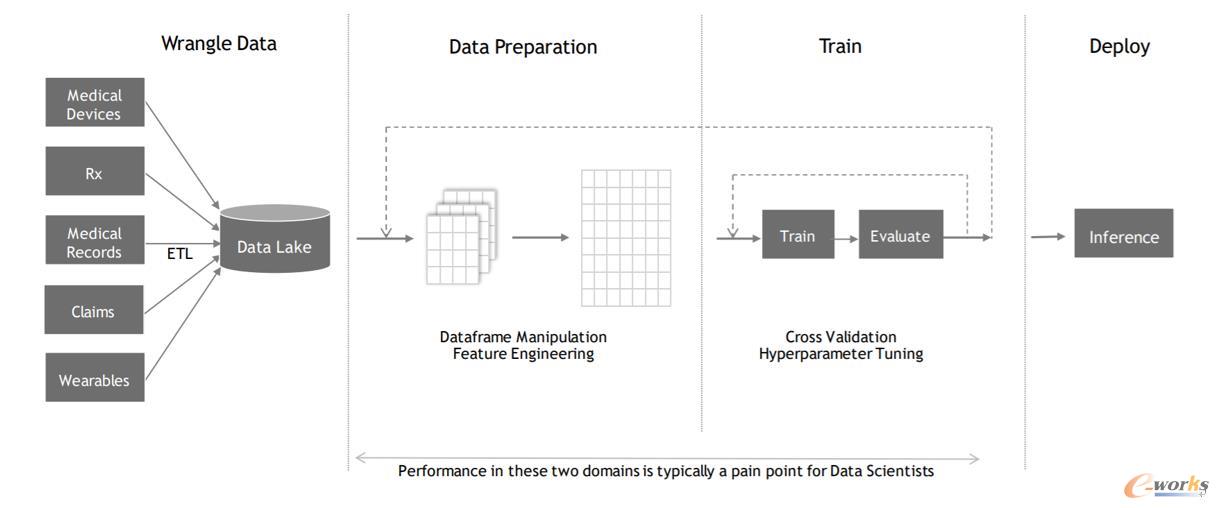
图 数据科学通用流程
目前,赵立威介绍包括HPE、IBM、Oracle、开源社区、创业公司等都在积极采用RAPIDS,显著提升端到端预测数据分析能力。例如沃尔玛已经采用RAPIDS实现了复杂模式大规模地运行,同时进行更加精准的预测。最后,他总结RAPIDS包含以下特点:
开源可定制,可扩展,可互操作:这里赵立威特别强调开源一方面是指NVIDIA支持并基于Apache Arrow构建,与PYTHON、SPARK、DASK等所有开源社区保持紧密合作;另一方面,因为RAPIDS本身的开源特性,未来也希望有跟多的开发者能够贡献代码,不断的完善平台、丰富它的基础特性、服务于更多的应用场景。
这里,赵立威展示了一个形象的例子,在过去数据工程师每天的大部分时间都在喝咖啡中度过,因为数据处理的过程中涉及到大量等待时间。应用RAPIDS后,相较于下图左边的等待时间,右图的效率得到了大大的提高,数据科学家可与更加专注与建模、测试与进行数据分析工作。RAPIDS为数据科学家提供了他们需要用来在 GPU 上运行整个数据科学管线的工具。最初的 RAPIDS 基准分析利用了 XGBoost 机器学习算法在 NVIDIA DGX-2™ 系统上进行训练,结果表明,与仅有 CPU 的系统相比,其速度能加快 50 倍。这可以帮助数据科学家将典型训练时间从数天减少到数小时,或者从数小时减少到数分钟,具体取决于其数据集的规模。
后摩尔时代下的GPU加速需求
减少培训时间:通过交互数据科学大幅提高工作效率;
开源生态提升数据分析能力
作为科技行业的热点,人工智能(AI)与机器学习正持续受到业界的关注。调研机构Gartner表示人工智能和先进的机器学习技术是被广泛关注的新兴技术,将在企业甚至整个行业中掀起革命浪潮。它们能够大幅度降低劳动力成本,产生意想不到的新见解,从原始数据中发现新模式,并建立预测模型。据分析师估计,面向数据科学和机器学习的服务器市场每年价值约为 200 亿美元,加上科学分析和深度学习市场,高性能计算市场总价值大约为 360 亿美元。
顶级模型精度:通过更快地迭代模型来提高机器学习模型的准确性,并更迅捷地实现部署;
众所周知,机器学习包含了数据、特征以及算法。赵立威介绍对于数据科学家而言,一个标准的系统流程是数据准备、数据训练与可视化呈现三个步骤,其中数据准备主要进行数据特征的提取、数据的合并以及降维等;数据训练则是一个不断循环的过程,通过参数调整、优化使精度更高;最后进行上线展示,从而进一步运营。


发表评论愿您的每句评论,都能给大家的生活添色彩,带来共鸣,带来思索,带来快乐。